@michaelakerman Håller med dig att potentialen med öppna data och öppen källkod är stor. Däremot upplever jag att det offentliga har svårt att faktiskt påvisa nyttan för individen och samhället i de projekt som genomförs. Dvs att projektplanerna har en planerad nytta, men den uppstår inte alltid efter projekten. Skulle gärna se en dialog i detta forum där vi diskuterar nyttohemtagning.
1 gillning
Härligt med siffror! Jag tror liksom du att nyttohemtagningen kopplat till ett förbättrat informationsutbyte kan vara större än så. Vore spännande att se siffror på nyttohemtagningen av den eID som Migrationsverket tar fram för dem som idag saknar personnummer eller samordningsnummer, när det kan nyttjas av andra aktörer.
Jag vet att den officiella vägledning för nyttorealisering inom offentlig sektor som DIGG ansvarar för (och som tidigare var ESV:s ansvar) inte direkt tar hänsyn till nyttor som realiseras utanför den egna organisationen:
https://www.digg.se/utveckling-av-digital-forvaltning/nyttorealisering/
Det finns ett stort nätverk för nyttorealisering kopplat till vägledningen som numera drivs av DIGG och som förmodligen borde kopplas ihop mer med nätverk om öppna data och öppen källkod.
I samband med att DIGG tar fram nyttoanalyser för den förvaltningsgemensamma digitala infrastrukturen som etableras under 2021 och framåt så kommer det också att krävas nya modeller för att värdera nyttor som realiseras av andra organisationer utifrån ett större samhällsperspektiv. Det bör rimligen gå hand i hand med frågor kring nyttorealisering för öppna data och öppen källkod.
Sven-Erik, Detta låter som en jättebra idé att koppla ihop dessa nätverk. Åtminstone genom att börja med ett workshoptema som där vi tittar på nyttorna, men också diskuterar vad som är rimliga kostnader.
Ja, det känns som ett tydligt behov framöver som DIGG också borde kunna samordna via sina olika ansvarsområden för öppna data och nyttorealisering.
1 gillning
Att mäta nyttan av både öppna data och öppen programvara hade definitivt varit intressant att undersöka vidare. Min magkänsla är dock att det kan bli svårt att ta hänsyn till alla nyttor som kan komma ut. Vissa är mjuka, andra hårda, och därav olika lämpliga att kvantifiera i kronor och ören. Tror snarare man får identifiera de olika nyttorna och se dem var för sig (ex. antal kopplade nyanställningar, förbättrat rykte bland olika intressenter, möjligheten att påverka marknadens riktning, minskad underhållsbudget, externt utförd utveckling/tillförd data som varit till intern nytta, effekt från nya produkter och tjänster av tredje part osv). För att få en helhetsbild tror jag man får ta till flertalet indikatorer och föra ett bredare resonemang snarare än att ge en summa av X miljoner som sparats/tjänats.
Ett alternativ som kan vara intressant att titta närmre på är Total cost of ownership, se ex. denna rapport från England -> https://eprints.lse.ac.uk/39826/1/Total_cost_of_ownership_of_open_source_software_(LSERO).pdf
1 gillning
Det är kul att se hur Svenska myndigheter äntligen ser Öppen källkod som en viktig strategi.
Tyvärr ser och hör jag många saker som jag personligen inte tror på utifrån vad jag lärt mig under de snart 18 år jag varit aktiv inom olika Open Source initiativ. Jag tror att mycket som görs idag tyvärr är ganska bortkastade investeringar.
Det jag personligen alltid letar efter i ett open source projekt är engagemang, dvs användarbas och hur aktivt ett projekt är. Finns det aktiva användare (från många organisationer) som diskuterar vad som skulle vara bra förbättringar osv. Det är nästan bara i dessa projekt som jag ser hållbara långsiktiga lösningar som har en chans att leva över tid. Undantag finns, men då ofta i fall där projekten är extremt små ofta i form av små tekniska byggstenar som vänder sig mot målgruppen utvecklare.
Jag skulle vilja påstå att contributors är det enda sättet man kan mäta värde på inom open source.
Det är alltid en stor varningsflagga när contributors bara kommer från en organisation, då har man antingen inte öppnat upp för samarbeten eller så ser ingen annan någon nytta med det man skapat.
En annan varningsflagga är när projekten är “färdiga system”, vilket är en av anledningarna till att man inte får några följare.
Tänk om myndigheter istället för att skapa nya projekt kunde engagera sig mer i redan stora och etablerade open source projekt och göra insatser som direkt kan få spridning och followers (utan dem inget skapat värde). Det skulle tex kunna handla om att göra bidrag som ökar på säkerheten, tillgängligheten eller prestandan för projekt som redan har miljontals följare.
Det är som sagt väldigt kul att se hur det bubblar inom myndighetsvärlden och det vill jag gärna försöka bidra till så att vi maximerar nyttan med dessa insatser.
3 gillningar
Håller med @tomper00 - det här är en väldigt kul utveckling!
Ser också ett stort hinder med att börja bygga eget från grunden istället för att bidra till existerande projekt som ändå fungerar bra - även om myndigheten som organisation kanske behöver göra vissa anpassningar.
En annan fördel för myndigheter är att surfa på vågen med existerande FOSS-projekt. Det möjliggör att kunna imponera på fler potentiella medarbetare som annars kanske inte kunnat tänka sig arbeta för myndigheter. Jag menar inte att det är bra att falla in i tech-trender och hoppa på det allra senaste bara för att.
Dessutom brukar typiskt sett myndigheter ha skattemedel för IT som kan gå till den organisation, oftast stiftelse, som underhåller och utvecklar FOSS-projekten, som ofta har brist på just finansiering för att bli mer framgångsrika. Detta är rimligt istället för att plöja ned dessa medel i licenser, kostsam egen utveckling och linjärt ökande konsultkostnader som kommer med teknikskulden av att bygga eget eller underhålla gamla proprietära system.
Driver DIGG arbetet med nyttorealisering framåt eller håller man det bara under armarna hjälpligt? Jag har fått uppfattningen att det inte riktigt finns det driv och stöd som kanske egentligen behövs.
Jag tycker också att man behöver se nyttorealisering tillsammans med behovsdriven utveckling och den vägledningen ligger ju kvar på eSam. Det vore verkligen bra om DIGG också tog behovsdriven utveckling på större allvar. Jag brukar säga att arbete med behovsdriven utveckling är den enskilt största förbättringen offentlig sektor kan göra. Om man inte arbetar behovsdrivet så är risken stor att även om projektet lyckas så misslyckas man eftersom man strävat mot fel målbild.
1 gillning
Björn, jag delar din uppfattning om att DIGG kan göra mer inom nyttorealisering och jag vet att det pågår ett särskilt arbete inom DIGG just nu för att ta fram nyttoanalyser för den framtida förvaltningsgemensamma digitala infrastrukturen som DIGG ska ha helhetsansvaret för. Där handlar det i stort om samma typ av frågor som för öppna data, dvs hur man beräknar nytta för tjänster och infrastruktur som primärt ska nyttjas av andra organisationer.
Att koppla ihop nyttorealisering med behovsdriven utveckling ser jag också som en mycket viktig fråga och eSams gamla vägledning skulle nog behöva moderniseras och övertas av DIGG för att främja en fortsatt digitalisering som fokuserar på verkligt värdeskapande före den teknikdrivna utvecklingen mot AI, RPA, IoT och inte minst Blockchain som vi ofta ser i praktiken påhejad av olika leverantörer.
Ja att DIGG tar över behovsdriven utveckling och vägledningen vore riktigt bra. Jag var besviken på att det inte skedde i samband med allt annat men förstår att det var mycket för DIGG ändå där med liten budget och stort uppdrag…
Roligt att nyttorealisering ändå lever inom myndigheten!
I en av gruppdiskussionerna i den senaste workshopen så var det någon som just förordade att myndigheterna som börjar med open source med fördel börjar med att just bidra i redan existerande och väl fungerande open source-projekt för att lära sig och se hur det fungerar i praktiken.
Det tyckte jag var väldigt vist. Det är lättare att börja med att bidra och vara framgångsrik och se nytta med det som man bidrar med. Att göra källkod tillgänglig och få ut någon nytta av det är mycket svårare. Sen kan ju i och för sig öppenhet vara en nytta i sig, men kanske mer indirekt.
1 gillning
Superbra inlägg! Det du skriver kring contributors är viktigt. Det vi liksom många myndigheter gör om alls, är att lägga koden på Github eller Gitlab, och så är det bra med det. Jag tror att vi behöver fundera på vad vi delar och varför. Om vi vill att andra ska kunna ta del av vår kod så behöver vi kommunicera kring detta precis på samma sätt som vi behöver kommunicera kring våra öppna data. Om om den ska bli användbar så är det bra om vi involverar andra tidigt i processen. Men HUR gör vi detta på ett bra sätt och vilken teknik är av intresse för andra? Ska vi fokusera på privata aktörer inom vår domän, eller ska vi försöka ta fram lösningar som skalar mot fler offentliga aktörer?
Att först försöka bidra i redan existerande forum och projekt innan man startar sitt eget tror jag är en väldigt bra idé. Frågan är dock om detta är så lätt som det verkar. Min upplevelse är att många initiativ (iaf jag) kommer ofta till slutsatsen att behovsbilden är för unik för att kunna återanvända ett redan befintligt system. Att våga komma till slutsatsen att merparten av ens lösning kan återanvändas och man inte är unik i det man gör kräver någon form av attitydförändring. Gillar det Bengt säger, men tror samtidigt att det kräver ett visst mod/insikt.
Behovsbilden är ett argument jag ofta hör som ett problem, men där tror jag personligen man helt enkelt ofta inte har en tillräckligt stor förståelse för skillnader mellan tjänsten man skapar dvs organisationens implementering av ett eller flera system med eventuell tillhörande egen kod och just systemen man tänker sig köpa in.
Givetvis finns det tillfällen då ett system kan lösa behovet fullt ut, men så snart man ger sig in i att arbeta med komplexa lösningar så kommer det aldrig att finnas ett system för detta och att då leta system baserat på enskilda features är direkt skadligt.
Det man måste leta efter i fall med komplexa implementationer är system som gör organisationen kapabel att leverera över tid.
Om det är något open source mjukvaror är extra starkt på så är det att tillhandahålla generiska lösningar som både är utbytbara och integrerbara mot andra system. De är ofta även säkrare och mer tillgänglighetsanpassade.
Det öppnar upp för att ändra saker över tid eller att byta ut delar som inte funkade som man tänkt osv.
Jämförelsen med proprietära system som ofta kan verka mer färdiga (i form av mer features) så skapar de i stället ofta funktionella inlåsningar som gör det svårt att ändra saker. Vi får antingen förlita oss på att leverantören skall lösa saker eller på de produkter man väljer att erbjuda integrationer till osv.
Det är även i behovsbilden problemen uppstår när man delar med sig egentligen, dvs när vi delar med oss av lösningar som inte är generiska utan som motsvarar organisationens sätt att lösa problem på.
Vi skapar då samma typ av inlåsning som proprietära system gör.
Personligen tror jag man behöver bli bättre på att upphandla kapacitet till utveckling snarare än det extrema funktionsfokus som finns idag.
Kikar vi på digitala innovativa bolag som Spotify, Google, AirBnB Facebook osv så skulle de aldrig någonsin bygga en tjänst med något annat än open source produkter som bas just av ovanstående anledningar.
Det hämmar helt enkelt innovationskraften.
2 gillningar
Öppna upp iform av koppla ihop och ha gemensamma persistenta identifierare
Exempel kul grej som hände idag så skrev Patrik Bernhardt Webbstrateg/projektledare, SCB kl. 11.40 på Wikipedia/Bybrunnen länk och undra om dom kunde lägga in länkar till SCB från kommunsidor…
Några svarade på sidan / jag ringde upp honom och medans vi prata så insåg vi att dom har unika identifierare for kommunerna i kommunkoder som vi hade i Wikidata så jag gjorde en POC en användare Larske inser samma sak som jag och gör ett utkast som sedan uppdateras och finns på alla kommunsidor som i sv:Wikipedia har ung. 2,5 miljon besökare per år med länk SCB
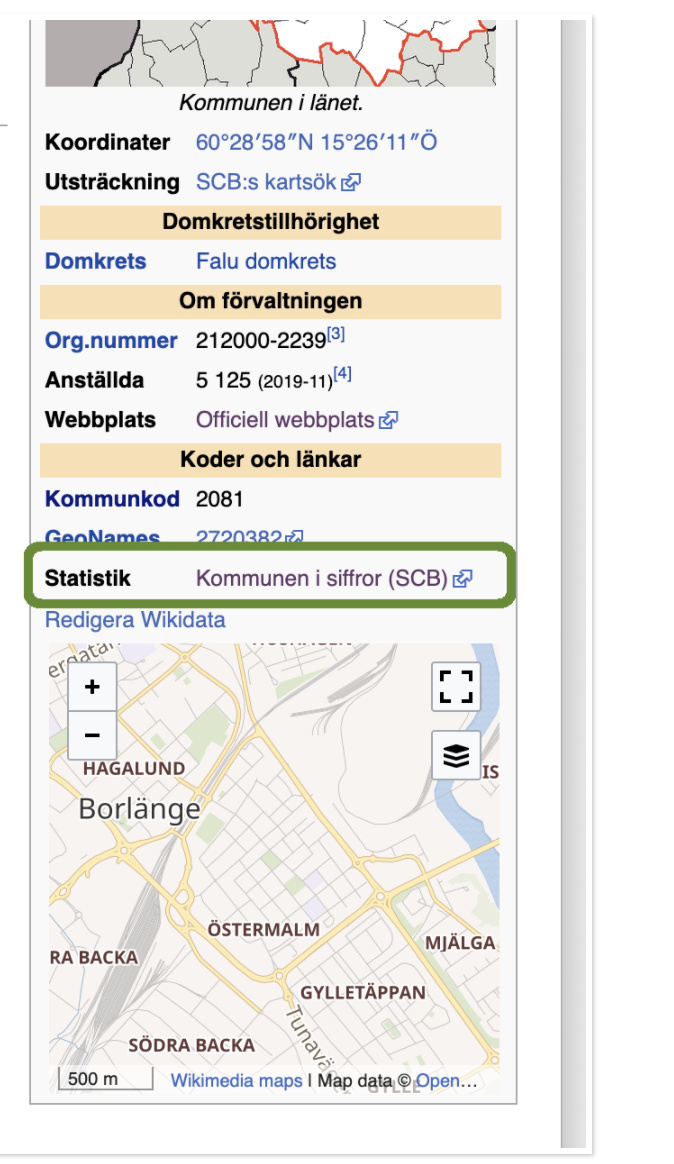
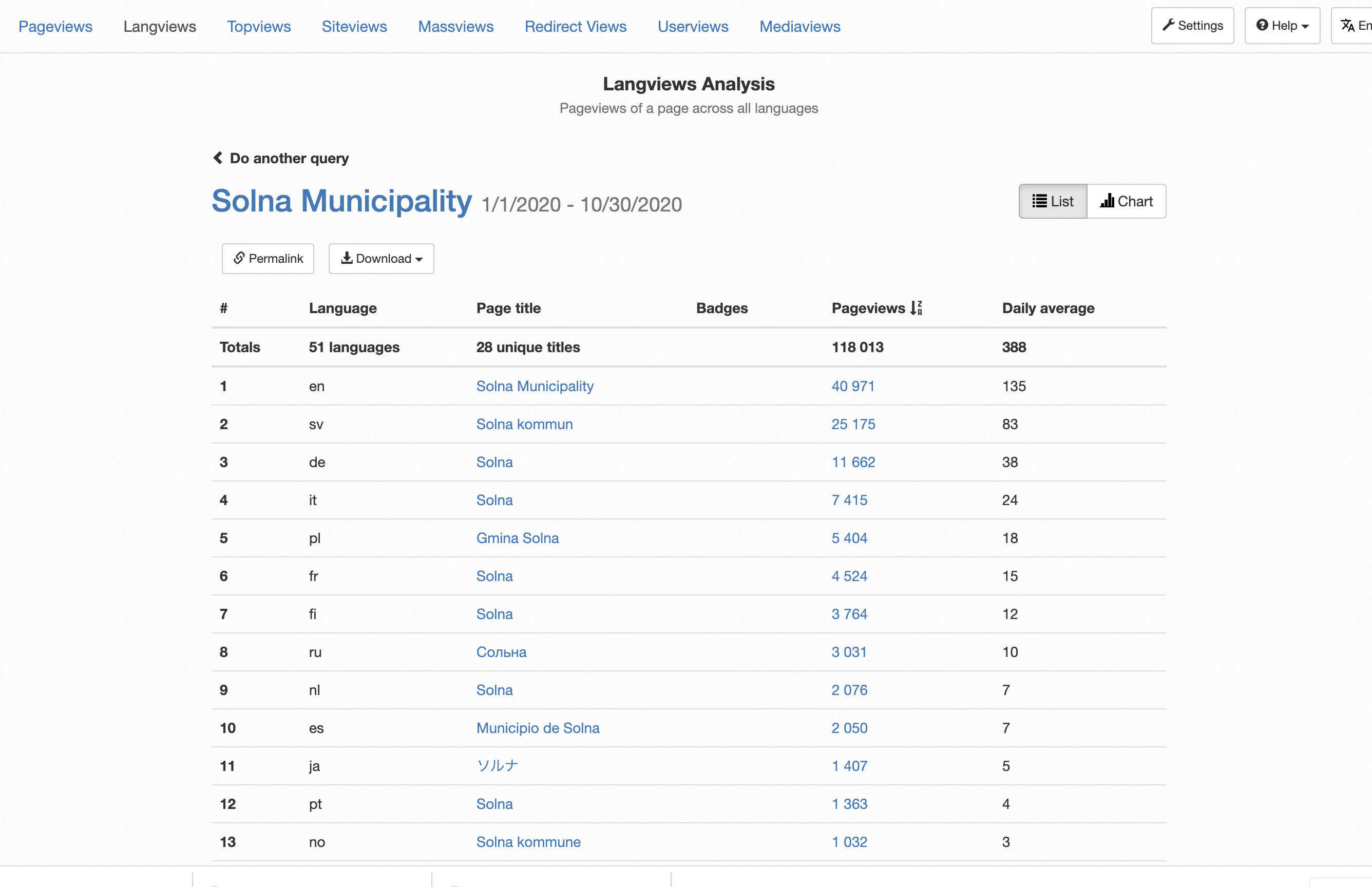
Intressant är att tittar man på Solna kommun så finns den sida på 51 språk och den engelska wikipedia sidan har nästan dubbelt så många läsare som den svenska → SCB borde kanske leverera sina sidor på fler språk?
Kostnad SCB
- 5 rader på Bybrunnen 30 minuter
- sidlänkar från alla kommunsidor hos en av världens 10 största plattformar stat en / stat sv (finns man i Wikidata kommer man ofta högre hos Google se hur Google läser WD ändringsströmmen se twitter
Framgångsfaktorer
- enkelt att kommunicera med Wikipedia alla kan skriva
- stor community som vill något - 7100 aktiva redigerare
- sid URLar hos SCB baserade på stabila kommunkoder
- snygga sidor som på ett tydligt sätt förklarar något som känns rätt att länka från Wikipedia
- Wiki världen har bra byggblock som mallar = DRY / Wikidata
5-1) hade SCB haft engelska sidor så skulle vi lika enkelt kunna länka på en:Wikipedia - en “svaghet” med Wiki världen att allt är decentraliserat och ett öppet nätverk så ena stunden snackar man med en raketforskare och nästa en glad amatör med sin egen agenda… så att få andra språkversioner att anamma ett koncept är enormt jobbigt idag se hur jag jobbat ihop med Nobelprize.org för att bli av med länkröta
5-2) Svenskt kvinnobiografiskt lexikon (SKBL) levererar sina sidor på engelska/svenska så där finns länkar hos en:Wikipedia se “Svenskt kvinnobiografiskt lexikon” vi kör även dagliga jämförelser mellan Wikidata/SKBL för att se skillnader
Nästa steg
-
jag hoppas vi får till möte och jag visar Wikidata / snackar öppen data och vad Wiki världen har för krav se T266870 kanske kan Wiki världen med 300 språk göra det enklare för SCB med att stödja flera språk vi har dels Wikidata / Lexikografiskt projekt (alla världens ord på alla världens språk med böjningsformer skall byggas upp… / Wikispeech på G / och startat upp Abstract Wikipedia
-
sidan om kommunerna tycker jag borde ha arbetsmarknads info så jag berättade får honom om JobTech och detta forum och workshopen i veckan… några tankar om detta (SCB är nere under helgen men sidan för Borlänge nås på https://kommunsiffror.scb.se/?id1=2081&id2=null )
-
andra varianter jag skulle vilja se kopplade till kommunerna (kanske inte skall vara hos SCB) är beslut som berör kommunen och dess framtid
** Riksdagen har bra Öppen data (se video /blog “Analysera rikspolitiken med hjälp av Wikidata” ) där några Wikidata volontärer har lyft in motioner SOU:er SFS:er och Högsta domstols beslut så nu kan vi med SPARQL se vilka som skrev motioner ihop 2018 eller se Anna Linds motioner hon skrev ihop med andra…

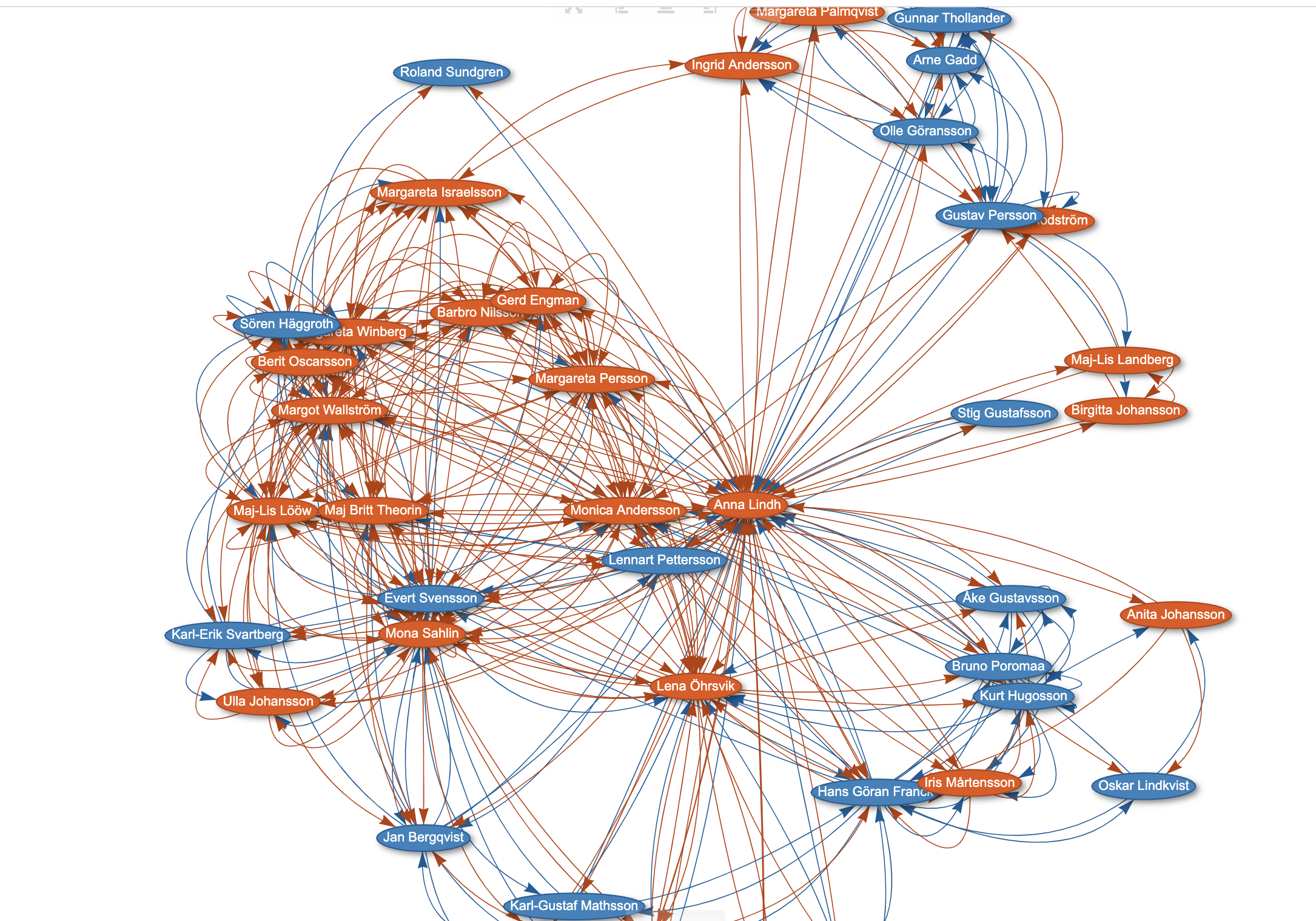
*** här kan man se hur skevt saker och ting är. Riksdagen om jag fattar rätt (pratade med dom 2019) har sitt öppna data som bas för sin snygga web (youtube) MEN dom har inte diariet som strukturerat länkade data vilket vi skulle vilja för att se vilka som dom skickar ut sina remisser till, Linköpings kommun har sitt diarie online men sender/receiver är bara strängar vi vill se länkade data dvs. unika identifierare till dom de skickar WE NEED THINGS NOT STRINGS

*** jag jobbade med en liten grej ihop med Paul-Olivier Dehaye mannen som avslöjade Facebook i Cambridge Analytica skandalen och han vill se att vi som medborgare med ett klick kan se alla beslut i Europa som berör AI strategier. Jag ser precis samma behov med strukturerad data och klassificering vilka beslut som tagits om COVID-19 i varje kommun dvs. vi behöver data som är Länkade data och kan koppla ihop beslut på EUnivå Riksdagsnivå och lokalnivå idag finns som sagt öar som Riksdagensdata som är bra. Exempel på initiativ som eldsjälar på Wikipedia skapar skrivstugor för att röra sig åt det hållet
Det är enorma utmaningar och det behövs enormt med dialog
Skall detta funka så är min tro att skapa Agila organisationer med Publika Prioriterade Backlogs är enda vägen framåt att få löst kopplade organisationer att skapa mervärde ihop…
Steg 1) skapa förtroende mellan Öppna löst kopplade nätverk - “Introduction to strategic doing”
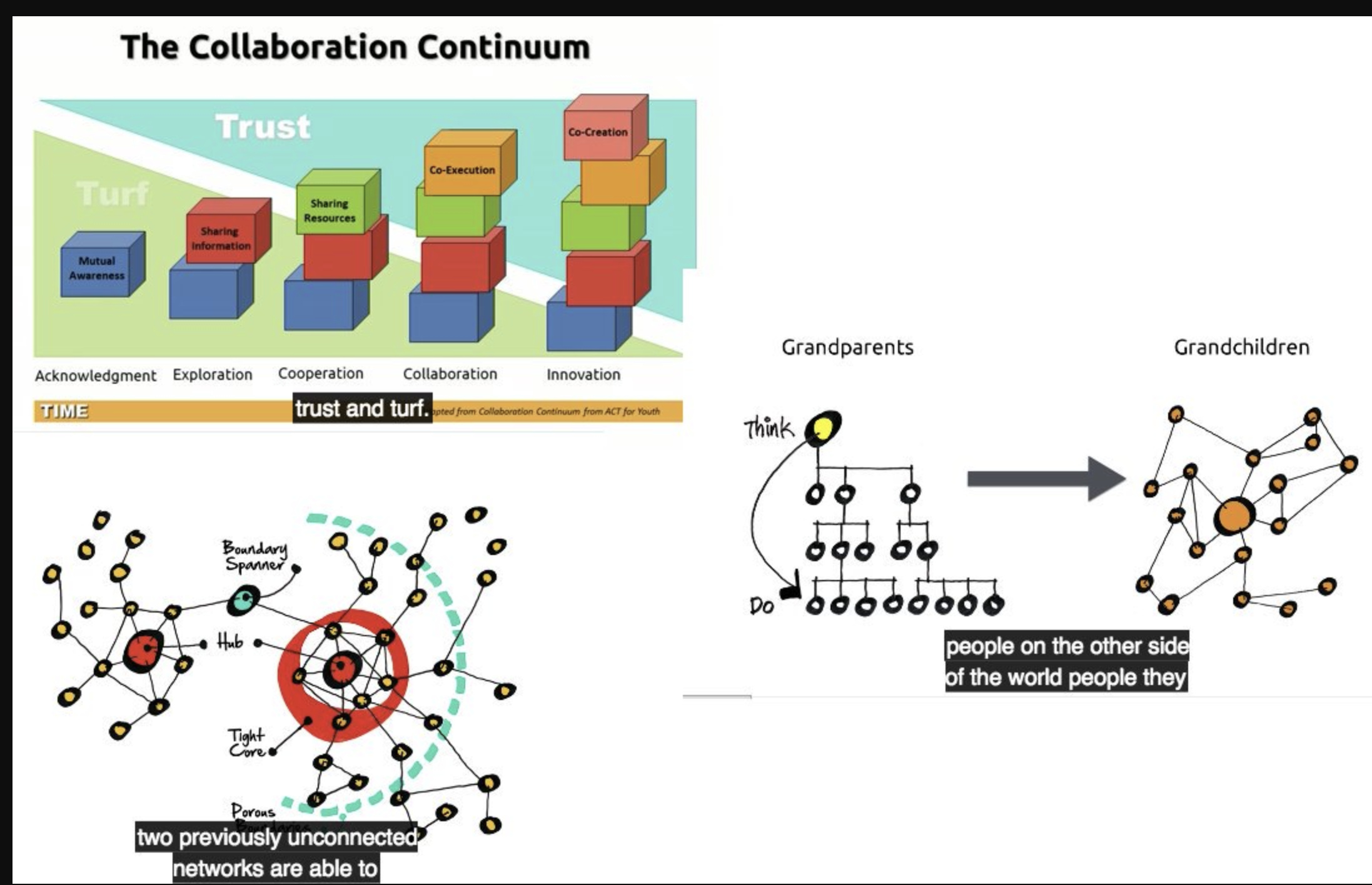 där cocreation är målet att vi skapar något ihop som vi ensamma inte kan göra
där cocreation är målet att vi skapar något ihop som vi ensamma inte kan göra
- Kanske SCB WIKipedia är detta där WIikipedia har > 410 000 aktiva editors bara på en:WIkipedia
- WHO sträckte ut handen i veckan och sätter rätt licens på sitt Covid material så Wikipedia kan använda det se “Wikipedia and W.H.O. Join to Combat Covid-19 Misinformation” dvs. vi är på nivå Collaboration men det finns enormt mycket att göra på data nivå… jag började handjaga COVID när det bröt ut men kravbilden har sedan dess blivit en helt annan… dvs. vi måste vara Agila… och ha personer med rättkompetens på båda sidor …

@salgo60 Ett axplock av koncept från jobtech taxonomy:
[
{
“taxonomy/id”: “zRtu_fYj_XC4”,
“taxonomy/type”: “skill”,
“taxonomy/definition”: “Projektering”,
“taxonomy/preferred-label”: “Projektering”
},
{
“taxonomy/id”: “rEeE_DXA_Q4h”,
“taxonomy/type”: “occupation-name”,
“taxonomy/definition”: “Skogsvärderare”,
“taxonomy/preferred-label”: “Skogsvärderare”
},
{
“taxonomy/id”: “i1fg_DHq_kfx”,
“taxonomy/type”: “ssyk-level-3”,
“taxonomy/definition”: “Övriga administrations- och servicechefer”,
“taxonomy/preferred-label”: “Övriga administrations- och servicechefer”
},
…
]
ID-begreppet består av en UUID (universally unique identifier) som kan skapas decentraliserat och fungerar bra för lagring med låg risk för krockar.
URI för ett koncept (kompetens, yrke, kommun etc) blir då följande som i sig är persistent.
https://taxonomy.api.jobtechdev.se/v1/taxonomy/main/concepts?id=zRtu_fYj_XC4
Finns det några förbättringsförslag på hur vi bygger upp våra URI:er som skulle göra det enklare och tryggare att länka till de?
1 gillning
Jag har i min backlog att sätta mig in i er taxonomy och koppla SSYK mot objekt i WIkidata det jag ser som bra mönster i Wikdata. Eftersom jag hänger på Wikipedia stor del av min tid så reagerar jag att jag inte ser språk taggar vilket känns som ett måste med en framtida arbetsmarknad återkommer med mer tankar
Lite spontana tankar
- Persisteta identifierare - Check
- Versionshistorik på alla objekt så man kan vad gar hämt med ett objekt exempel Q3440237 = Arbetsförmedlingen
- Se diff mellan 2 versioner ex. Arbetsförmedlingen 2015-2019
- vi är en öppen plattform --> vi måste ha även möjlighet att rulla tillbaka vandalisering
- by design har vi stöd > 200 språk se Q3440237 en sv zh ar ttl / json / jsonld
- skall jag matcha era objekt så underlättar om ni har “same as”
- stöd för att merga objekt dvs. är 2 objekt samma som så har vi owl:sameas och pekar om det gamla objektet till det nya
Återkommer