Öppna data-utredningens huvudbetänkande Innovation genom information, SOU 2020:55, har skickats ut på remiss med sista svarsdag den 17 december 2020. Den går att ladda ner i sin helhet från Regeringens webbplats. Vill eller hinner man inte läsa alla 488 sidor innan utfrågningen rekommenderas att läsa sammanfattningen (s. 21-32) och de avslutande författningskommentarerna och lagförslaget (s. 389-430). Björn Hagströms sammanfattning är också ett lästips.
En fråga kring öppen källkod kopplat till den nya Öppna data-lagstiftningen:
Det finns ett antal domar https://www.allmanhandling.se/2017/06/07/kallkod-for-myndighetsprogram-var-offentlig/ som indikerar att en myndighets källkod är att betrakta som offentlig handling. I praktiken så har inte myndigheter haft ett krav på sig att lämna ut systemet digitalt dock. Så min fråga/härledning ”till lagstiftaren” är om alla myndigheters källkod bör betraktas och tillhandahållas till alla i om den nya lagen.
En fråga kring öppna licenser för öppna data: PRV håller på att ta fram en vägledning för offentlig sektor hur vi ska tänka kring öppna licenser. Mitt antagandet är att denna vägledning inte påverkas av den nya lagstiftningen. Stämmer det antagandet?
Fråga från Open Knowledge Fundation: Varför understrykes inte transparens och öppenhet i det övergripande syftet med lagen? (“Syftet är att stödja utvecklingen av informationsmarknaden och stimulera innovation genom att öka tillgängliggörande och vidareutnyttjande av information från myndigheter och offentliga företag, särskilt i form av öppna data.”)
Fråga 2 från Open Knowledge Fundation: Är det tänkt att skyldigheten att publicera en beskrivning av information som görs tillgänglig (exempelvis på Sveriges dataportal) bara kommer gälla information som görs tillgänglig utan en begäran? Varför inte också den information som görs tillgänglig med en begäran? Det skulle ge mycket mer data.
Fråga 3 från Open Knowledge Fundation: Vad innebar detta i praktiken? “Vidare ska offentliga aktörer sträva efter att information tillhandahålls i format som är öppna och maskinläsbara, i den utsträckning det inte inverkar på kärnverksamheten.”
Vad är definitionen av begreppet data i detta sammanhang? I sammanfattningen används termerna data och information lite synonymt, och i exemplen används till övervägande del skrivna dokument. Data är ju dock ett väldigt generellt begrepp. Mediafiler, loggfiler, källkodsfiler (som Maria nämner ovan) och databaser för att nämna några exempel består också av data - avser den föreslagna lagen att inbegripa även detta?
Vad är definitionen av begreppet öppen i detta sammanhang? Det minimala kravet för att kunna kalla något öppet torde vara att något är tillgängligt för läsning. Hur ställer man sig till användning, modifiering och vidarespridning? Är det tillåtet, och under vilka villkor?
“I första hand ska information tillhandahållas i befintliga format. … Vidare ska offentliga aktörer sträva efter att information tillhandahålls i format som är öppna och maskinläsbara, i den utsträckning det inte inverkar på kärnverksamheten.” Denna formulering, förvisso från sammanfattningen, riskerar kanske att göra lagen till en pappersanka. Myndigheter är stora användare av proprietär programvara med slutna format. Om det räcker med att hänvisa till att det inverkar på kärnverksamheten att konvertera data från ett slutet till ett öppet format för att slippa tillhandahålla data, så finns det nog en viss risk att många kommer välja den enkla vägen.
Tackar såg denna utfrågning och fick en klump i magen vid 1:48:15 där ställs frågan till Anna Swedlund
om konsekvenserna av en datadriven arbetsmarknad
jag fick en känsla att Anna inte förstår frågan om en datadriven arbetsmarknad…
några reflektioner över detta?
är JobTech för osynliga? har ni underskattat vikten av att vara visionära och kommunicera detta när inte ens regeringens utredare förstår frågan? Än mindre gissar jag har dom tagit höjd för att tänka nytt i sitt uppdrag…
som gammal Scrummaster tror jag på att vara agil och många med mig skall Sverige bli bäst i världen och tänka nytt så får vi nog bygga om “myndighetsbilen” så att dom har folk som kan se framåt är min tro… i den “galenskap” Wikipedia världen är så röstar vi fram ung 50 nya egenskaper per månad och har nu > 8000 egenskaper dvs. ingenting vi kunde se 2012 när projektet startade och hela tiden diskuteras kunskapsgrafen och kopplingar i verktyg som Telegram
Det kan eventuellt vara svårt för utredningen att svara på men kan svara kort från mitt perspektiv. DIGG och PRV har under arbetets gång haft utgångspunkt av det uppdaterade direktivet och annan relaterad lagstiftning som nämns i policydokumentet. Rekommendationen kommer på så vis i tillämpliga delar som en vägledning för direktivets skrivelser kring licenser. Lagförslaget reglerar inte specifikt licens-frågan utan gör bedömningen att det även fortsatt snarast är i policydokument och riktlinjer som de offentliga aktörerna bör arbeta med att ta fram gemensamma licenser och att främja användningen av sådana. Det är vad DIGG:s och PRV:s arbete har handlat om.
@salgo60: Jag reflekterade också över att arbetsmarknadsdata inte inte definieras som särskilda värdefulla datamängder. Det speglar väl hur jag uppfattar hur vi ser på olika domäner och vilka förväntningar vi har på varandra inom offentlig sektor. Jag ser att frågan är större än bara kopplat till utredningen, för själva författningsförslaget påverkar inte hanteringen av data från oss negativt. Tvärtom. Vi gör tolkningen att vi fortsatt ska dela med oss av den data vi kan och att vi ska fokusera på att göra detta i öppna format, öppna standarder och tillsammans med öppen teknik - proaktivt, precis som vi försöker göra idag. Däremot kan man väl se det som en hemläxa för oss att faktiskt försöka värdera och kommunicera nyttan av att vi tillgängliggör öppna data. Detta är en del av bakgrunden till varför vi initierat nätverket kunskapsdelning öppna data & öppen källkod.
Japp kommunikation är svårare än man tror. Särskilt förklara detta med kunskapsgrafer är galet svårt. Gissar att alla inte är raketingenjörer och tittar jag på museerna så skapades Digisam 2012 för att bättre Digitalisera kulturarvet och dom utreder fortfarande.,… jag gjorde en aktivitet med data från Europeana som är ett Europa projekt startat 2012 med Länkade data för att samla ihop objekt från museerna och har idag 55 miljoner objekt och det visar sig att det gör så dåligt att en:Wikipedia vägrade länka dom (längre blog om text strängar vs. things och att dom inte vet vem Carl Larsson) dvs. ingen av dom svenska museerna har ett fungerande tänk hur man berättar att vi har konstnär A som är samma som museums B konstnär B1 … i den galna WIkidata världen har vi nu passerad 100 miljoner objekt där vi säger samma som > 200 språk…
Jag är lite rädd att vi ser samma problem med Öppen data att man försöker köra racet med samma laguppställning som man alltid har och att kunskapsförnyelse sker när en medarbetare fyller 65…
OT: Kunskapsgrafer och jobbmatchning jag försöker läsa in mig på området och hittade Textkernel som verkar jobba med både kunskapsgrafer och jobbmatchning… något ni tittat på vad de gör!!!
User case Jobtech
Varför inte tänka utanför boxen? jag blir lite mörkrädd av att man sitter i Almedalen eller skapar hackathon och tror att man blir bäst i världen men aldrig pratar om hur laget skall förändras
Förslag test case JobTech
ta fram skill matrix på vad som krävs för att lyckas med att leverera Öppen data
krydda denna soppa med lite förslag på nyanställningar och/eller kompetens behov
följ upp detta med en dashboard som över tid mäter “insamlad kundnytta”/organisationens kompetens förändring etc…
Det antipattern jag ser inom kultursektorn är att man har evighetsanställningar, ingen tydlig målbild och det man gör är skapar lite Hackhaton och sedan händer inget mer
en liten kul grej är att det Digisam utreder med länkade data vann jag ett Hackathon 2016. En ung kille i vårat team från Indien gjorde en video på några timmar som överträffar det jag sett Digisam producera sedan 2012 länk…
Det inkom många frågor under utfrågningen i chatten som tyvärr ej hann besvaras. Dessa finns samlade i ett Google-dokument, men tyvärr har utredningssekreteraren inte haft tid att besvara dem pga intensivt arbete med slutbetänkandet.
Har ni fortsatt frågor kring utredningen kan ett tips vara att ställa dem här i forumet så kanske det finns andra i nätverket som kan svara på dem!
Det kom önskemål om ytterligare ett event innan remissvar ska in och samarbete kring att skriva. Dessa har vi hörsammat och vi är nu ett antal organisationer som gått samman för att samla våra synpunkter i ett gemensamt dokument: http://bit.ly/sou202055 Det är sedan upp till varje organisation att plocka de delar och tankar man själv håller med om i sina remissvar.
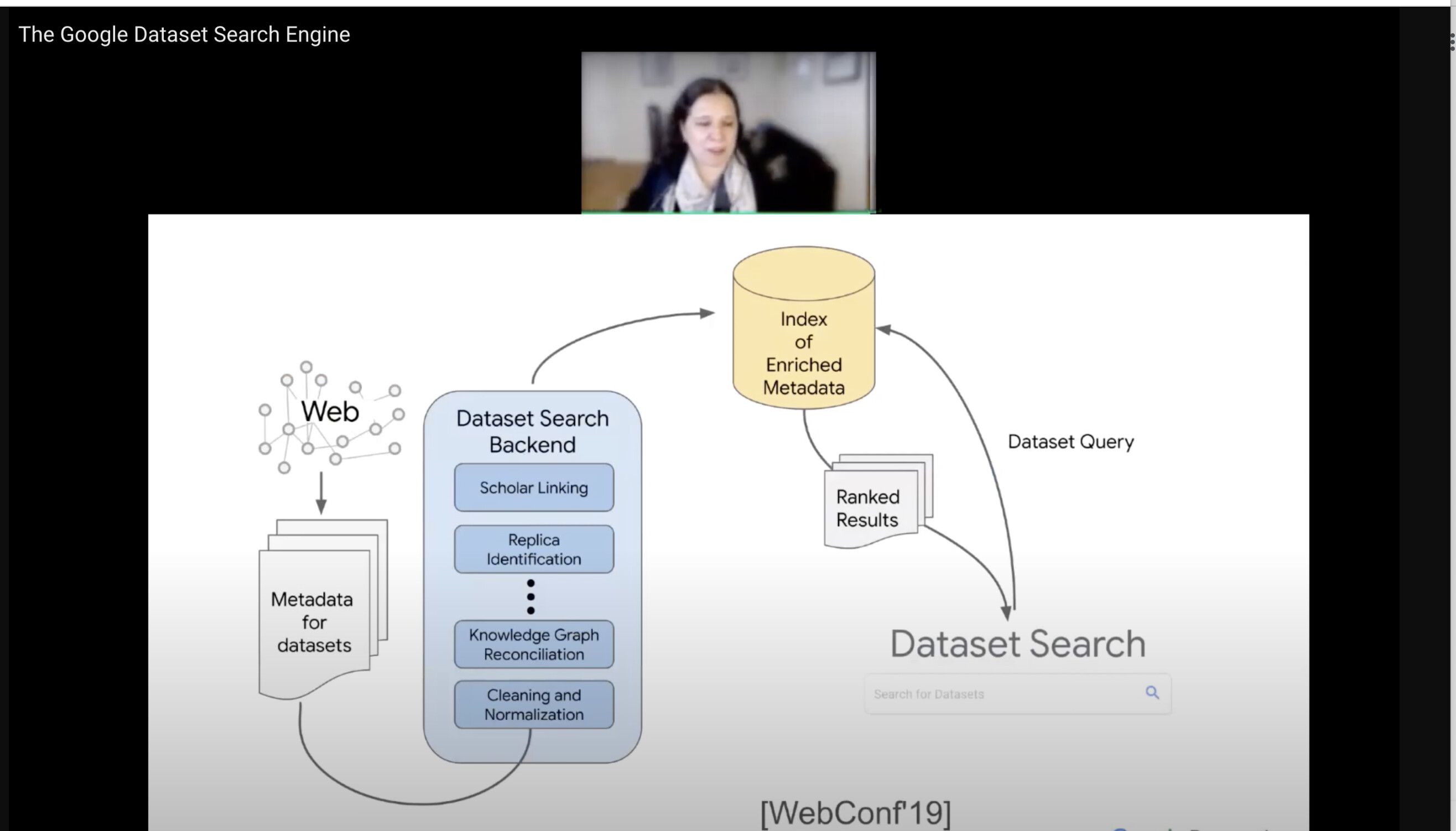
Varken svenska Dataportalen eller den Europeiska eller Grunddata utredningen ser jag berör detta med kunskapsgrafer men Google dataset search engine lyfter fram det för att göra Dataset och Öppen data användbara och enkla att upptäcka
Min oro
Springer Öppen data åt fel håll som inte fokuserar på att lyfta in Kunskapsgrafer i ekvationen utan tror det är att flytta runt kassar med data så blir alla glada
Vem skulle kunna driva detta?
Jag hade i våras ett samtal med DIGGs AI ansvarig och han visste inte vad en kunskapsgraf är dvs. DIGG verkar inte se möjligheterna med kunskapsgrafer utan är nog mer dom som räknar kassar med data som ställts ut i skogen.
Ja! Du har helt rätt i att det finns ett stort behov av att koppla ihop olika dataset. Wikidata är väl alldeles utmärkt start! Eller vad säger mina kollegor som jobbar med Taxonomin? @davidnorman@Petter@henrik_suzuki